DeepSeek推出NSA技術(shù):加速長(zhǎng)文本處理與推理
在AI技術(shù)飛速發(fā)展的今天,長(zhǎng)文本處理一直是自然語言處理領(lǐng)域的難點(diǎn)。DeepSeek團(tuán)隊(duì)近期推出了一項(xiàng)名為NSA(Natively Sparse Attention)的技術(shù),為這一領(lǐng)域帶來了革命性的突破。本文將詳細(xì)介紹NSA技術(shù)的核心原理、創(chuàng)新點(diǎn)、實(shí)驗(yàn)結(jié)果及應(yīng)用前景。

NSA技術(shù)簡(jiǎn)介: NSA是一種專為現(xiàn)代硬件優(yōu)化的稀疏注意力機(jī)制,旨在加速長(zhǎng)文本的訓(xùn)練和推理過程,同時(shí)顯著降低預(yù)訓(xùn)練成本。與傳統(tǒng)的全注意力模型相比,NSA通過動(dòng)態(tài)分層稀疏策略,結(jié)合粗粒度的標(biāo)記壓縮和細(xì)粒度的標(biāo)記選擇,保留了全局上下文感知能力和局部精度。
關(guān)鍵創(chuàng)新點(diǎn):
-
硬件對(duì)齊優(yōu)化:NSA的設(shè)計(jì)與現(xiàn)代硬件緊密對(duì)齊,通過算術(shù)強(qiáng)度平衡的算法設(shè)計(jì),最大化稀疏注意力的效率。
-
端到端訓(xùn)練支持:NSA支持從預(yù)訓(xùn)練到推理的全流程訓(xùn)練,減少訓(xùn)練成本,同時(shí)保持模型性能。
-
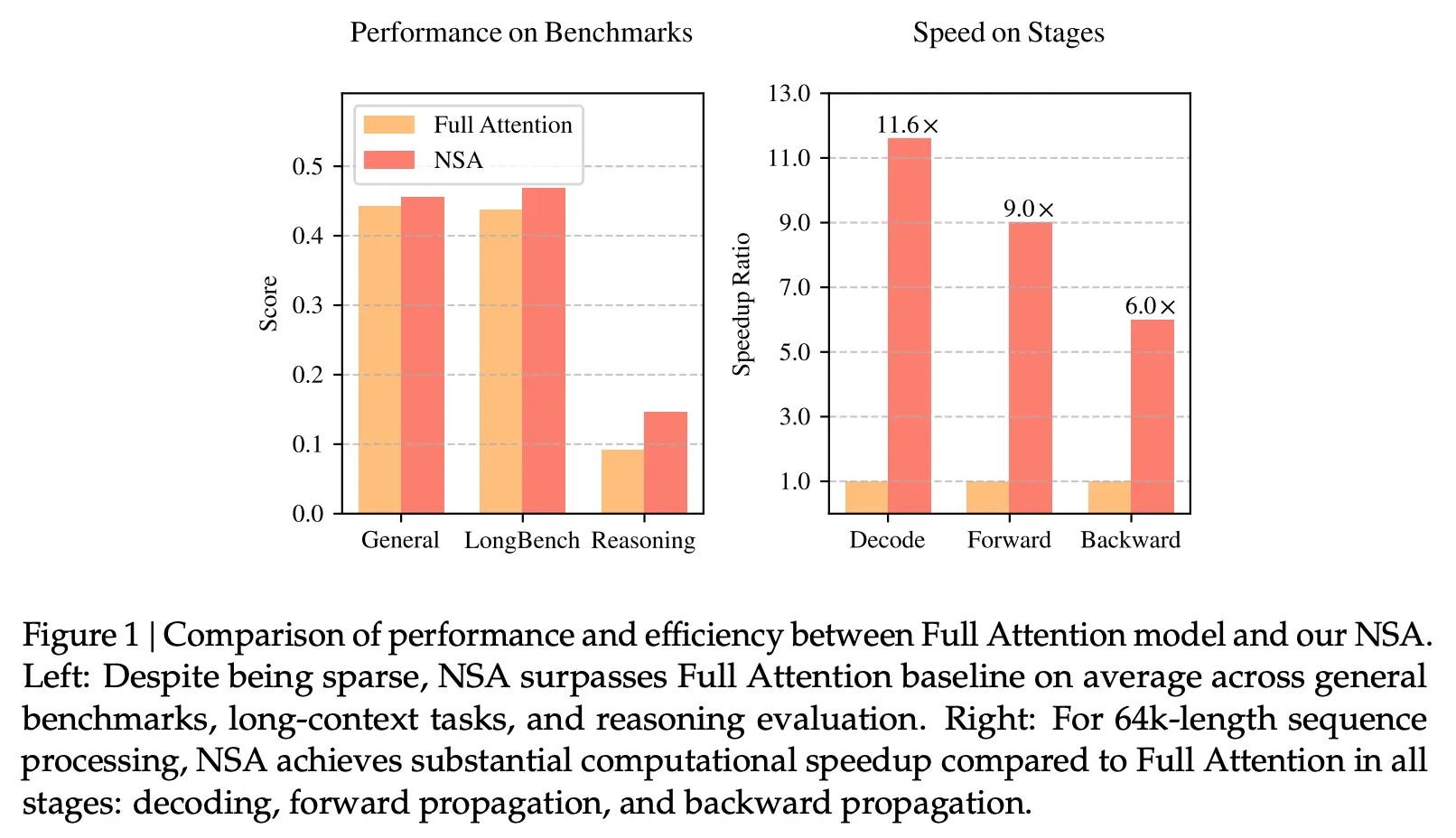
顯著的效率提升:在處理64k長(zhǎng)度的序列時(shí),NSA在解碼、前向傳播和反向傳播等各個(gè)階段都實(shí)現(xiàn)了顯著的速度提升,最高可達(dá)11.6倍。
實(shí)驗(yàn)結(jié)果: 在多個(gè)基準(zhǔn)測(cè)試中,NSA的表現(xiàn)不僅沒有下降,反而超越了全注意力模型。特別是在長(zhǎng)文本任務(wù)和基于指令的推理中,NSA展現(xiàn)了卓越的性能。例如,在64k長(zhǎng)度的序列處理中,NSA在所有階段均實(shí)現(xiàn)了顯著的加速。
應(yīng)用前景: NSA技術(shù)的應(yīng)用前景廣闊,尤其在長(zhǎng)文本處理、實(shí)時(shí)交互系統(tǒng)和資源受限環(huán)境中具有重要意義。未來,NSA有望在代碼生成與調(diào)試工具、超長(zhǎng)文檔分析的智能助手以及科研、教育等領(lǐng)域的長(zhǎng)文本推理任務(wù)中發(fā)揮重要作用。
未來展望: DeepSeek的NSA技術(shù)不僅為長(zhǎng)文本建模帶來了新的突破,還為稀疏注意力領(lǐng)域提供了全新的思路。隨著技術(shù)的不斷發(fā)展,NSA有望加速下一代大型語言模型在長(zhǎng)文本處理領(lǐng)域的應(yīng)用落地。
結(jié)語: DeepSeek的創(chuàng)始人梁文鋒親自參與了這項(xiàng)研究,展現(xiàn)了其在技術(shù)創(chuàng)新方面的領(lǐng)導(dǎo)力。這一成果不僅在技術(shù)上具有重要意義,也為人工智能在教育、內(nèi)容創(chuàng)作和高端自然語言處理應(yīng)用中的發(fā)展開辟了新的可能性。NSA的發(fā)布標(biāo)志著人工智能領(lǐng)域在長(zhǎng)文本處理能力上邁出了重要一步,為未來的發(fā)展奠定了堅(jiān)實(shí)基礎(chǔ)。



















